


O ácido desoxirribonucleico (ADN, em português: ácido desoxirribonucleico; ou DNA, em inglês: deoxyribonucleic acid) é um composto orgânico cujas moléculas contêm as instruções genéticas que coordenam o desenvolvimento e funcionamento de todos os seres vivos e alguns vírus, e que transmitem as características hereditárias de cada ser vivo. A sua principal função é armazenar as informações necessárias para a construção das proteínas de ARNs. Os segmentos de ADN que contêm a informação genética são denominados genes. O restante da sequência de ADN tem importância estrutural ou está envolvido na regulação do uso da informação genética.
A estrutura da molécula de ADN foi originalmente descoberta por Rosalind Franklin. No entanto, o Prémio Nobel de Fisiologia ou Medicina de 1962 foi entregue ao norte-americano James Watson e ao britânico Francis Crick, que se inspiraram em Franklin e demonstraram o funcionamento e a estrutura em dupla hélice do ADN em 7 de Março de 1953, juntamente com Maurice Wilkins.
Do ponto de vista químico, o ADN é um longo polímero de unidades simples (monômeros) de nucleotídeos, cuja cadeia principal é formada por moléculas de açúcares e fosfato intercalados unidos por ligações fosfodiéster. Ligada à molécula de açúcar está uma de quatro bases nitrogenadas mantidas juntas por forças hidrofóbicas. A sequência de bases ao longo da molécula de ADN constitui a informação genética. A leitura destas sequências é feita por intermédio do código genético, que especifica a sequência linear dos aminoácidos das proteínas. A tradução é feita por um ARN mensageiro que copia parte da cadeia de ADN por um processo chamado transcrição e posteriormente a informação contida neste é "traduzida" em proteínas pela tradução. Embora a maioria do ARN produzido seja usado na síntese de proteínas, algum ARN tem função estrutural, como por exemplo o ARN ribossômico, que faz parte da constituição dos ribossomos.
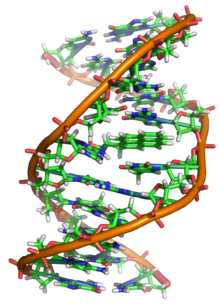
Dentro da célula, o ADN pode ser observado numa estrutura chamada cromossoma durante a metáfase. O conjunto de cromossomas de uma célula forma o cariótipo. Antes da divisão celular os cromossomas são duplicados por meio de um processo chamado replicação. Eucariontes como animais, plantas, fungos e protozoários têm o seu ADN dentro do núcleo enquanto que procariontes como as bactérias o têm disperso no citoplasma. Dentro dos cromossomas, proteínas da cromatina como as histonas compactam e organizam o ADN. Estas estruturas compactas guiam as interacções entre o ADN e outras proteínas, ajudando a controlar que partes do ADN são transcritas.
Propriedades físicas e químicas

O ADN é um longo polímero formado por unidades repetidas chamadas nucleotídeos. A cadeia de ADN tem 2,2 a 2,4 nanómetros de largura, e um nucleotídeo possui aproximadamente 0,33 nanómetros de comprimento. Embora os monômeros (nucleotídeos) que constituem o ADN sejam muito pequenos, os polímeros de ADN podem ser moléculas enormes, com milhões de nucleotídeos. Por exemplo, o maior cromossomo humano (cromossomo 1), possui 220 milhões de pares de bases de comprimento. Uma molécula de ADN do ser humano possui aproximadamente dois metros de comprimento, encapsulada em um núcleo celular de 6 µm, o equivalente a acomodar uma linha de 40 km de comprimento em uma bola de tênis.
Em organismos vivos, o ADN não existe como uma molécula única (cadeia simples), mas sim como um par de moléculas firmemente associadas. As duas longas cadeias de ADN enrolam-se como uma trepadeira formando uma dupla hélice. Os nucleotídeos estão presentes em ambas as cadeias da dupla hélice, unidos com nucleótidos da mesma cadeia por ligações fosfodiéster e à cadeia complementar por meio de pontes de hidrogénio formadas pelas suas bases. Em geral, uma base ligada a um açúcar é chamada nucleosídeo e uma base ligada a um açúcar e um ou mais fosfatos é chamada nucleotídeo. Portanto, o ADN pode ser referido como um polinucleotídeo.

A cadeia principal do ADN é formada por fosfato e resíduos de açúcar, dispostos alternadamente. O açúcar no ADN é 2-desoxirribose, uma pentose (açúcar com cinco carbonos). Os açúcares são unidos por grupos fosfato que formam ligações fosfodiester entre o terceiro e quinto átomos de carbono dos anéis de açúcar adjacentes. Estas ligações assimétricas significam que uma cadeia de ADN tem uma direção. Numa dupla hélice, a direção dos nucleotídeos de uma cadeia é oposta à direção dos nucleotídeos da outra cadeia. O formato das cadeia do ADN é designado antiparalelo. As terminações assimétricas das cadeias de ADN são designadas terminais 5' (cinco linha) e 3' (três linha). Uma das diferenças principais entre o ADN e o ARN encontra-se no açúcar, com a substituição da 2-desoxirribose no ADN pela ribose no ARN.
A dupla hélice do ADN é estabilizada por pontes de hidrogênio entre as bases presas às duas cadeias. As quatro bases encontradas no ADN são a adenina (A), citosina (C), guanina (G) e timina (T). Estas quatro bases ligam-se ao açúcar/fosfato para formar o nucleotídeo completo.
Estas bases são classificadas em dois tipos; a adenina e guanina são compostos heterocíclicos chamados purinas, enquanto que a citosina e timina são pirimidinas. Uma quinta base (uma pirimidina) chamada uracila (U) aparece no ARN e substitui a timina, a uracila difere da timina pela falta de um grupo de metila no seu anel. A uracila normalmente não está presente no ADN, só ocorrendo como um produto da decomposição da citosina. Exceções para esta regra são os fagos AR9, 3NT, I10, bem como o PBS1 (muito utilizado em pesquisas), que contém uracila no seu ADN, em vez de timina.

|

|
Emparelhamento de bases
Cada tipo de base numa cadeia forma uma ligação com apenas um tipo de base na outra cadeia. Este comportamento é designado de complementariedade de bases. Assim, as purinas formam pontes de hidrogênio com pirimidinas, i.e. A liga-se com T e C com G. Este arranjo de dois nucleotídeos complementares na dupla hélice é chamado par de bases. Além das pontes de hidrogênio entre as bases, as duas cadeias são mantidas juntas devido a forças geradas por interações hidrofóbicas entre as bases empilhadas, a qual não é influenciada pela sequência do ADN. Como as pontes de hidrogênio não são ligações covalentes, podem ser quebradas e reunidas com relativa facilidade. Desta forma, as duas fitas da dupla hélice de ADN podem ser separadas como um zíper (fecho de correr) por força mecânica ou altas temperaturas. Como resultado desta complementariedade, toda a informação contida numa das cadeias de ADN está também contida na outra, o que é fundamental para a replicação do ADN.
Os dois tipos de pares de base formam diferentes números de pontes de hidrogênio: AT forma duas pontes de hidrogênio enquanto que GC formam três pontes de hidrogênio. Desta forma a interação entre GC é mais forte que AT. Como resultado, a percentagem de GC numa dupla fita de ADN determina a força de interação entre as duas cadeias. Uma parte da dupla cadeia de ADN que precisa de ser separada facilmente, tal como a TATAAT Caixa de Pribnow nos promotores bacterianos, tende a ter sequências com maior predomínio de AT, para facilitar a abertura da dupla cadeia aquando da transcrição. No laboratório, a força desta interacção pode ser medida encontrando a temperatura necessária para quebrar as pontes de hidrogénio, a temperatura de desnaturação (também chamado Tm). Quando todos os pares de base numa dupla hélice de ADN quebram as suas ligações, as duas cadeias separam-se e existem em solução como duas moléculas completamente independentes. Estas moléculas de ADN de cadeia simples não têm uma única forma comum, mas algumas conformações são mais estáveis do que outras.
Sulcos
O ADN normalmente encontra-se em forma de uma espiral dextrógira (gira para a direita, ou no sentido horário). Portanto, as duas cadeias de nucleotídeos giram uma sobre a outra e acabam por formar sulcos entre as cadeias de fosfato, deixando expostas as faces das bases nitrogenadas que não estão unidas por pontes de hidrogênio com a base complementar.
Há dois tipos de sulcos na superfície da dupla hélice: um com 22 Å denominado sulco maior e um com 12 Å designado de sulco menor.
A principal função dos sulcos do ADN é fornecer a informação acerca das bases que se encontram ligadas numa determinada região da dupla cadeia sem necessidade de abertura. O sulco maior oferece maior acessibilidade para ligação com proteínas do que o sulco menor. Um exemplo disto é a TBP (TATA-binding protein) uma importante proteína para a transcrição em eucariotas.
Senso e antissenso
Uma sequência de ADN é chamada de senso se possui a mesma sequência do ARNm. A cadeia oposta (complementar) à cadeia "senso" é denominada sequência antissenso. Como a ARN polimerase sintetiza um ARN que é complementar à fita molde, então podemos dizer que ela utiliza a cadeia anti-senso como molde para produzir um ARN. As sequências senso e anti-senso podem existir em diferentes partes da mesma cadeia de ADN, que pode ser de um lado ou do outro, dependendo de onde se encontra a sequência codificadora.
Às vezes não é possível dizer qual é a cadeia senso ou antissenso. Isto acontece devido à existência de genes que se sobrepõem. Neste caso ambas as cadeias dão origem a um ARN. Nas bactérias, a sobreposição pode estar envolvida da regulação da transcrição.
Nos vírus, a sobreposição aumenta a capacidade do armazenamento de informações em pequenos genomas virais.
Superenrolamento
O ADN pode ser torcido num processo denominado superenrolamento. No estado relaxado do ADN, uma fita normalmente dá uma volta completa ao eixo da dupla hélice a cada 10,4 pares de base, mas se o ADN está torcido, as cadeias ficam mais ou menos enroladas.
Se o ADN está torcido na direção da hélice, é denominado um superenrolamento positivo e as bases estão unidas mais firmemente. Já o superenrolamento negativo refere-se a uma torção na direção oposta, resultando num afrouxamento das bases. Na natureza, o ADN apresenta um ligeiro superenrolamento negativo que é causado pela ação da enzima topoisomerase.
Estas enzimas também são necessárias para aliviar o estresse de torção causado no ADN durante os processos de transcrição e replicação.
Estrutura alternativa da dupla hélice

O ADN pode existir em muitas formações diferentes. As formações mais comuns são: ADN-A, ADN-B, ADN-C, ADN-D, ADN-E, ADN-H, ADN-L, ADN-P, e ADN-Z.
Porém, só as formações de ADN A, B e Z foram encontradas em sistemas biológicos naturais. A formação que o ADN adopta depende de vários fatores da própria sequência de ADN: a intensidade e direção do superenrolamento, modificações químicas das bases e a solução na qual o ADN está presente (ex.: concentração de metais, iões e poliaminas).
Das três formações referidas, a forma “B” é a mais comum nas condições encontradas nas células.
A forma “A” corresponde à espiral dextra mais larga, com um sulco menor largo e superficial e um sulco maior estreito e profundo. A forma “A” ocorre sob condições não fisiológicas em amostras de ADN desidratadas, enquanto na célula pode ser produzida por pareamento híbrido de ADN e ARN ou pelo complexo enzima-ADN.
Em segmentos de ADN onde as bases foram quimicamente modificadas por metilação, o ADN pode sofrer uma grande modificação na sua formação e adoptar a forma ADN-Z. A cadeia gira sobre o eixo da dupla hélice para a esquerda, o oposto da forma mais comum – ADN-B.
Esta estrutura é rara e pode ser reconhecida por proteínas especificas de ligação com o ADN-Z. Pode estar envolvida na regulação da transcrição.
Estruturas em quadrúplex
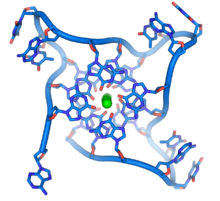
Nas extremidades do cromossomas lineares estão zonas especializadas do ADN chamadas telómeros. A função principal destas regiões é permitir que a célula replique as extremidades do cromossoma usando a enzima telomerase, porque enzimas que permitem replicar ADN normalmente não conseguem copiar as extremidades 3' dos cromossomas. Estas tampas de cromossoma especializadas também ajudam a proteger as extremidades do ADN, e evitam que o sistema de reparação de ADN elimine estas regiões como erros que precisassem de ser corrigidos. Em células humanas, os telómeros têm normalmente vários milhares de repetições de uma sequência simples (TTAGGG).
Estas sequências ricas em guanina podem estabilizar as extremidades dos cromossomas formando estruturas de unidades de quatro bases empilhadas, ao invés dos pares de base usuais encontrados em outras moléculas de ADN. Quatro bases de guanina formam uma placa chata e depois estas unidades chatas de quatro bases empilham-se no topo umas das outras, para formarem estruturas quadrúplex-G estáveis. Estas estruturas são estabilizadas por pontes de hidrogénio entre as margens das bases e por quelação de um ião metálico no centro de cada unidade de quatro bases. Outras estruturas podem também ser formadas, com o conjunto central de quatro bases provenientes de uma cadeia simples enrolada à volta das bases ou de diversas cadeias paralelas, cada uma contribuindo com uma base para a estrutura central.
Além destas estruturas empilhadas, os telómeros também formam grandes estruturas em forma de laço chamados telomere loops ou T-loops. O ADN de cadeia simples enrola-se à volta de um círculo grande estabilizado por proteínas que se ligam a telómeros. Mesmo no fim dos T-loops, o ADN de cadeia simples do telómero é mantido sobre uma região de ADN de cadeia dupla pela cadeia do telómero que desestabiliza o ADN de dupla hélice e o emparelhamento de bases de uma das duas cadeias. Esta estrutura de cadeia tripla é chamada de laço de deslocamento ou D-loop.
Modificações químicas
|

|

|
| citosina | 5-metilcitosina | timina |
Modificações de bases
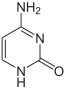
A expressão de genes é influenciado pela maneira como o ADN está disposto nos cromossomas, numa estrutura chamada cromatina. As modificações de bases podem estar envolvidas na disposição, com as regiões quem tem expressão génica baixa ou inexistente contendo usualmente níveis elevados de metilação de citosina. Por exemplo, a metilação de citosina produz 5-metilcitosina, que é importante na inactivação do cromossoma X. O nível médio de metilação varia entre organismos - o verme Caenorhabditis elegans tem pouca metilação da citosina, enquanto que vertebrados têm níveis mais elevados, com até 1% do seu ADN contendo 5-metilcitosina Apesar da importância da 5-metilcitosina, esta pode desaminar transformando-se em timina. Citosinas metiladas são por isso especialmente susceptíveis de sofrer mutações. Outras modificações de bases incluem metilação de adeninas em bactérias e glicosilação do uracilo para produzir a "base-J" em organismos da classe Kinetoplastida.
Danos ao ADN
O ADN pode ser danificado por muitos tipos diferentes de mutagénios, que alteram a sequência de ADN. Estes incluem agentes oxidantes, agentes alquilantes e também por radiação electromagnética de grande energia tal como luz ultravioleta e raios-X. O tipo de dano ao ADN produzido depende do tipo de mutagénio. A luz ultravioleta, por exemplo, pode danificar o ADN produzindo dímeros de timina, que são ligações cruzadas entre pirimidinas. Por outro lado, oxidantes como radicais livres ou peróxido de hidrogénio produzem múltiplos tipos de danos, incluindo modificações de bases, em particular guanosina, e quebras das cadeias duplas. Em cada célula humana, cerca de 500 bases podem sofrer danos por oxidação por dia. As quebras da cadeia dupla são lesões oxidativas de difícil reparação, que podem produzir mutações pontuais, inserções e delecções, assim como translocações cromossómicas.
Muitos mutagénios encaixam entre o espaço entre dois pares de bases adjacentes, na chamada intercalação. A maioria dos intercaladores são aromáticos e moléculas planas e incluem brometo de etídio, daunomicina, doxorrubicina e talidomida. Para que um intercalador encaixe entre pares de bases, as bases têm de se separar, abrindo a cadeia dupla. Isto inibe a transcrição e a replicação do ADN, causando toxicidade e mutações. Como resultado, os intercaladores de ADN são muitas vezes carcinogénicos. Benzopireno, acridinas, aflatoxina e brometo de etídio são exemplos bem conhecidos. No entanto, devido à sua capacidade de inibir a transcrição e replicação, estas toxinas também são usadas em quimioterapia para inibir o crescimento rápido de células tumorais.
Funções biológicas
O ADN ocorre normalmente como cromossomas lineares em eucariotas e como cromossomas circulares em procariotas. O conjunto dos cromossomas numa célula perfazem o seu genoma; o genoma humano tem aproximadamente 3 mil milhões de pares de base dispostos em 46 cromossomas. A informação transportada pelo ADN está contida nas sequências de ADN chamados genes. A transmissão da informação dos genes é conseguida pela complementaridade do emparelhamento das bases. Por exemplo, na transcrição, quando uma célula usa a informação num gene, a sequência de ADN é copiado para uma sequência de ARN complementar por meio da atracção entre o ADN e os nucleotídeos de ARN correctos. Esta cópia de ARN pode ser depois usada para compor uma sequência proteica correspondente no processo de tradução, que depende da mesma interacção entre nucleotídeos de ARN. Alternativamente, uma célula pode simplesmente copiar a sua informação genética num processo chamado replicação do ADN.
Genes e genomas

O ADN genómico está localizado no núcleo celular dos eucariontes, assim como em pequenas quantidades em mitocôndrias e em cloroplastos. Em procariontes, o ADN está dentro de um corpo de forma irregular no citoplasma chamado nucleóide. A informação genética num genoma está nos genes, e o conjunto completo desta informação num organismo é chamado o seu genótipo. Um gene é a unidade básica da hereditariedade e é uma região do ADN que influencia uma característica particular num organismo. Genes contêm uma fase aberta de leitura que pode ser transcrita, assim como sequências reguladoras tais como promotores ou acentuassomos, que controlam a transcrição da fase aberta de leitura.
Em muitas espécies, apenas uma pequena fracção da sequência total do genoma codifica uma proteína. Por exemplo, apenas 1,5% do genoma humano consiste de exões (que codificam proteínas), com mais de 50% do ADN humano consistindo de sequências repetitivas. As razões para a presença de tanto ADN não codificante em genomas eucarióticos e as extraordinárias diferenças no tamanho do genoma, ou valor C, entre espécies representam um enigma conhecido por enigma do valor C. Contudo, sequências de ADN que não codificam proteínas podem ainda codificar moléculas de ARN não codificante funcional, que estão envolvidas na regulação da expressão génica.
Algumas sequências de ADN não codificante têm um papel estrutural nos cromossomas. Os telómeros e centrómeros contêm tipicamente poucos genes, mas são importantes para a função e estabilidade dos cromossomas. Uma forma abundante de ADN não codificante em humanos são os pseudogenes, que são cópias de genes que foram desabilitados por mutação. Estas sequências são usualmente apenas fósseis moleculares, apesar de poderem servir ocasionalmente como material genético em bruto para a criação de novos genes por meio do processo de duplicação de genes e divergência.
Transcrição e tradução

Um gene é uma sequência de ADN que contêm informação genética e pode influenciar o fenótipo de um organismo. Dentro de um gene, a sequência de bases ao longo de uma cadeia de ADN definem uma cadeia de ARN mensageiro, que por sua vez define uma ou mais sequências proteicas. A relação entre a sequência de nucleótidos de um gene e a sequência de aminoácidos de uma proteína é determinada pelas regras de tradução, conhecidas colectivamente como o código genético. O código genético consiste de 'palavras' de três letras chamadas codões formadas por uma sequência de três nucleótidos (p.e. ACU, CAG, UUU).
Na transcrição, os codões de um gene são copiados para um ARN mensageiro pela ARN polimerase. Esta cópia de ARN é depois descodificada por um ribossoma que lê a sequência de ARN emparelhando o ARN mensageiro com o ARN de transferência, que carrega aminoácidos. Uma vez que há quatro bases em combinações de 3 letras, há 64 codões possíveis ( combinações). Estas codificam os vinte aminoácidos, dando à maioria dos aminoácidos mais do que um codão possível. Há também três codões 'stop' ou 'nonsense' significando o fim da região codificante; estes são os codões UAA, UGA e UAG.

Replicação
A divisão celular é essencial para que um organismo cresça, mas quando uma célula se divide tem de replicar o ADN do seu genoma para que as duas células-filha tenham a mesma informação genética que a célula parental. A estrutura em dupla-hélice do ADN fornece um mecanismo simples para a sua replicação. As duas cadeias são separadas e sequências de ADN complementares a cada uma das cadeias são recriadas por uma enzima chamada ADN polimerase. Esta enzima constrói a cadeia complementar encontrando a base correcta por intermédio do emparelhamento com a base complementar, e ligando-a à cadeia original. Como as polimerases de ADN só conseguem fazer a extensão de uma cadeia de ADN na direcção 5' para 3', outros mecanismos são usados para copiar a cadeia antiparalela da dupla hélice. Desta forma, a base presente na cadeia antiga determina que base vai aparecer na nova cadeia e a célula acaba com uma cópia perfeita do seu ADN.
Interacções com proteínas
Todas as funções do ADN dependem de interacções com proteínas. Estas interacções com proteínas podem ser não específicas, ou a proteína pode ligar-se especificamente a uma única sequência de ADN. Algumas enzimas também se podem ligar ao ADN. Destas, as polimerases que copiam as sequências de ADN na transcrição e replicação são particularmente importantes.
Proteínas que se ligam ao ADN (DNA-binding)
|
Proteínas estruturais que se ligam ao ADN são exemplos bem estudados de interacções não específicas ADN-proteínas. Nos cromossomas, o ADN está ligado a proteínas estruturais formando complexos. Estas proteínas organizam o ADN numa estrutura compacta, a cromatina. Em eucariontes esta estrutura envolve a ligação do ADN a um complexo de pequenas proteínas básicas chamadas histonas, enquanto que em procariontes estão envolvidas vários tipos de proteínas. As histonas formam um complexo em forma de disco, o nucleossoma, que contém duas voltas completas de ADN de cadeia dupla à sua volta. Estas interacções não específicas formam-se quando os resíduos básicos das histonas fazem ligações iónicas ao esqueleto açúcar-fosfato acídico do ADN, e por isso são largamente independentes da sequência de bases. Modificações químicas nestes resíduos de amino-ácidos incluem metilação, fosforilação e acetilação. Estas mudanças químicas alteram a força da interacção entre o ADN e as histonas, tornando o ADN mais ou menos acessível a factores de transcrição e mudando a taxa de transcrição. Outras proteínas com ligação a ADN não específicas incluem o grupo de proteínas de alta mobilidade, que se ligam a ADN dobrado ou distorcido. Estas proteínas são importantes pois dobram conjuntos de nucleossomas e organizam-nos em estruturas maiores que constituem os cromossomas.
Um grupo distinto destas proteínas são as que se ligam especificamente a ADN de cadeia simples. Nos humanos, a proteína de replicação A é o membro desta família mais bem compreendido e é usado em processos onde a dupla hélice é separada, incluindo durante a replicação do ADN, recombinação e reparo. Estas proteínas parecem estabilizar ADN de cadeia dupla e protegem-no da formação de hairpin loops e da degradação por nucleases.
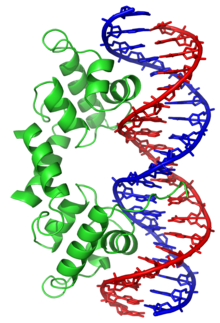
Em contraste, outras proteínas evoluíram de modo a ligar-se a sequências de ADN específicas. Os factores de transcrição são dos mais intensivamente estudados (proteínas que regulam a transcrição). Cada factor de transcrição liga-se a um conjunto particular de sequências de ADN e activa ou inibe a transcrição de genes que tenham estas sequências perto dos seus promotores. Os factores de transcrição fazem isto de duas maneiras. Primeiro, podem ligar-se à polimerase do ARN responsável pela transcrição, quer directamente quer por meio de proteínas mediadoras; isto posiciona a polimerase no promotor e permite que comece a transcrição. Em alternativa, os factores de transcrição podem ligar-se a enzimas que modificam as histonas no promotor; isto muda a acessibilidade do molde de ADN à polimerase.
Como estes locais de ligação podem ocorrer pelo genoma inteiro de um organismo, mudanças na actividade de um tipo de factor de transcrição pode afectar milhares de genes. Por consequência, estas proteínas são muitas vezes alvo de processos de transdução de sinal que controlam respostas a mudanças ambientais ou diferenciação e desenvolvimento celular. A especificidade da interacção destes factores de transcrição com o ADN provém das proteínas que fazem contactos múltiplos com a extremidade das bases de ADN, permitindo a leitura da sequência de ADN. A maior parte destas interacções com bases faz-se no sulco maior, onde as bases estão mais acessíveis.
Enzimas que modificam o ADN
Nucleases e ligases

As nucleases são enzimas que cortam as cadeias de ADN mediante a catálise da hidrólise das ligações fosfodiéster. As nucleases que hidrolisam nucleótidos a partir dos extremos das cadeias de ADN denominam-se exonucleases, enquanto que as endonucleases cortam no interior das cadeias. As nucleases que se utilizam com maior frequência em biologia molecular são as enzimas de restrição, endonucleases que cortam o ADN em sequências específicas. Por exemplo, a enzima EcoRV, mostrada à esquerda, reconhece a sequência de 6 bases 5′-GAT|ATC-3′ e faz um corte em ambas as cadeias na linha vertical indicada, gerando duas moléculas de ADN. Outras enzimas de restrição geram, no entanto, extremidades coesivas, já que cortam de forma diferente as duas cadeias de ADN. Na natureza, estas enzimas protegem as bactérias contra as infecções de fagos, ao digerir o ADN do fago quando entra através da parede bacteriana, actuando como um mecanismo de defesa. Em biotecnologia, estas nucleases específicas utilizam-se na clonagem molecular e na técnica de impressão de ADN ( fingerprinting, em inglês).
As enzimas denominadas ADN ligases podem reunir pedaços de ADN cortados ou quebrados. As ligases são particularmente importantes na replicação do ADN da cadeia atrasada de ADN, já que unem os fragmentos curtos de ADN gerados no garfo de replicação para formar uma cópia completa do molde de ADN. Também se utilizam no reparo de ADN e na recombinação genética.
Topoisomerases e helicases
As topoisomerases são enzimas que possuem actividade de nuclease e ligase. Estas proteínas mudam a quantidade de ADN superenrolado. Algumas destas enzimas funcionam cortando a hélice de ADN e permitindo a uma secção que faça rotação, de maneira a reduzir o grau de superenrolamento; uma vez feito isto, a enzima volta a unir os fragmentos de ADN. Outros tipos de enzimas são capazes de cortar uma hélice de ADN e depois passar a segunda cadeia de ADN através desta quebra, antes de reunir as hélices. As topoisomerases são necessárias para muitos processos em que intervém o ADN, como a replicação e a transcrição.
As helicases são proteínas que pertencem ao grupo dos motores moleculares. Utilizam energia química armazenada nos trifosfatos de nucleósidos, fundamentalmente ATP, para romper pontes de hidrogénio entre bases e separar a dupla hélice de ADN em cadeias simples. Estas enzimas são essenciais para a maioria dos processos em que as enzimas necessitam de aceder às bases do ADN.
Polimerases
As polimerases são enzimas que sintetizam cadeias de nucleótidos a partir de trifosfatos de nucleósidos. A sequência de seus produtos são cópias de cadeias de polinucleótidos existentes, que se denominam moldes. Estas enzimas funcionam adicionando nucleótidos ao grupo hidróxilo em 3' do nucleótido anterior numa cadeia de ADN. Por consequência, todas as polimerases funcionam na direcção 5′ → 3′. Nos sítios activos destas enzimas, o trifosfato de nucleósido que se incorpora emparelha a sua base com a correspondente no molde: isto permite que a polimerase sintetize de forma precisa a cadeia complementar ao molde.
As polimerases classificam-se de acordo com o tipo de molde que utilizam:
- Na replicação do ADN, uma ADN polimerase dependente de ADN realiza uma cópia de ADN a partir de uma sequência de ADN. A precisão é vital neste processo, por isso muitas destas polimerases possuem uma actividade de verificação de leitura (proofreading). Mediante esta actividade, a polimerase reconhece erros ocasionais na reacção de síntese, devido à falta de emparelhamento entre o nucleótido erróneo e o molde, o que gera um desacoplamento (mismatch). Se se detecta um desacoplamento, activa-se uma actividade exonuclease na direcção 3′ → 5′ e a base incorrecta é eliminada. Na maioria dos organismos, as ADN polimerases funcionam num grande complexo denominado replissoma, que contém múltiplas unidades acessórias, como helicases.
- As ADN polimerases dependentes de ARN são uma classe especializada de polimerases que copiam a sequência de uma cadeia de ARN em ADN. Incluem a transcriptase reversa, que é uma enzima viral implicada na infecção de células por retrovírus, e a telomerase, que é necessária para a replicação dos telómeros. A telomerase é uma polimerase inusual, porque contém o seu próprio molde de ARN como parte da sua estrutura.
- A transcrição é levada a cabo por uma ARN polimerase dependente de ADN que copia a sequência de uma das cadeias de ADN em ARN. Para começar a transcrever um gene, a ARN polimerase une-se a uma sequência do ADN denominada promotor, e separa as cadeias de ADN. Então copia a sequência do gene num transcrito de ARN mensageiro até que alcança uma região do ADN denominada terminador, onde se detém e se separa do ADN. Como ocorre com as ADN polimerases dependentes de ADN em humanos, a ARN polimerase II (a enzima que transcreve a maioria dos genes do genoma humano) funciona como um grande complexo multiproteíco que contém múltiplas subunidades reguladoras e acessórias.
Recombinação genética

|

|

Uma hélice de ADN normalmente não interage com outros segmentos de ADN. Nas células humanas os diferentes cromossomas ocupam áreas separadas no núcleo celular denominadas “territórios cromossómicos”. A separação física dos diferentes cromossomas é importante para que o ADN mantenha a sua capacidade de funcionar como um armazém estável de informação. Um dos poucos momentos em que os cromossomas interagem é durante o sobrecruzamento cromossómico (chromosomal crossover, em inglês), durante o qual se recombinam. O sobrecruzamento cromossómico ocorre quando duas hélices de ADN se rompem, sofrem intercâmbio e se unem novamente.
A recombinação permite aos cromossomas trocar informação genética e produzir novas combinações de genes, o que aumenta a eficiência da selecção natural e pode ser importante na evolução rápida de novas proteínas. Durante a profase I da meiose, uma vez que os cromossomas homólogos estão perfeitamente emparelhados formando estruturas que se denominam bivalentes, produz-se o fenómeno de sobrecruzamento ou entrecruzamento (crossing-over), no qual os cromatídeos homólogos não irmãos (procedentes do pai e da mãe) trocam material genético. A recombinação genética resultante faz aumentar em grande medida a variação genética entre a descendência de progenitores que se reproduzem por via sexual. A recombinação genética também pode estar implicada na reparação do ADN, em particular na resposta celular às roturas da dupla cadeia (double-strand breaks).
A forma mais frequente de sobrecruzamento cromossómico é a recombinação homóloga, na qual os dois cromossomas implicados compartilham sequências muito similares. A recombinação não homóloga pode ser danosa para as células, já que pode produzir translocações cromossómicas e anormalidades genéticas. A reacção de recombinação é catalisada por enzimas conhecidas como recombinases, tais como a RAD51. O primeiro passo no processo de recombinação é uma rotura da dupla cadeia, causada por uma endonuclease ou por dano no ADN. Posteriormente, uma série de passos catalisados em parte pela recombinase conduz à união das duas hélices formando pelo menos uma junção de Holliday, na qual um segmento de uma cadeia simples é anelada com a cadeia complementar na outra hélice. A junção de Holliday é uma estrutura de união tetraédrica que pode mover-se ao longo do par de cromossomas, intercambiando uma cadeia por outra. A reacção de recombinação detém-se pelo corte da união e a reunião dos segmentos de ADN libertados.
Evolução do metabolismo de ADN
O ADN contém a informação genética que permite à maioria dos organismos vivos funcionar, crescer e reproduzir-se. No entanto, desconhece-se o intervalo de tempo durante o qual ele exerceu esta função nos ~3000 milhões de anos desde a história da vida, já que se propôs que as formas de vida mais precoces poderiam ter utilizado ARN como material genético. O ARN poderia ter funcionado como parte central de um metabolismo primordial, já que pode transmitir informação genética e simultaneamente actuar como catalisador, formando parte das ribozimas. Este antigo mundo de ARN onde os ácidos nucleicos funcionariam como catalisadores e como armazéns de informação genética, poderia ter influenciado na evolução do código genético actual, baseado em quatro nucleótidos. Isto se deveria a que o número de bases únicas num organismo é determinado entre um número pequeno de bases (o que aumentaria a precisão da replicação) e um número grande de bases (que por sua vez aumentaria a eficiência catalítica das ribozimas).
Infelizmente, não dispomos de evidência directa dos sistemas genéticos ancestrais, porque a recuperação do ADN a partir da maior parte dos fósseis é impossível. O ADN é capaz de sobreviver no meio ambiente durante menos de um milhão de anos, e logo começa a degradar-se lentamente em fragmentos de menor tamanho em solução. Algumas investigações pretendem a obtenção de ADN mais antigo, como no caso do isolamento de uma bactéria viável a partir de um cristal salino de 250 milhões de anos de antiguidade, mas estes dados são controversos.
No entanto, podem utilizar-se ferramentas de evolução molecular para inferir os genomas de organismos ancestrais a partir de organismos contemporâneos. Em muitos casos, estas inferências são suficientemente fiáveis, de maneira que uma biomolécula codificada num genoma ancestral pode ser ressuscitada no laboratório para ser estudada hoje. Uma vez recomposta a biomolécula ancestral, suas propriedades poderiam oferecer informações sobre os ambientes primordial, remetendo ao campo emergente da paleogenética experimental. Apesar de tudo, o processo de trabalho retrospectivo tem limitações inerentes, razão pela qual outros investigadores tentam elucidar o mecanismo evolutivo trabalhando desde a origem da Terra até adiante no tempo. Dada suficiente informação sobre como as substâncias cósmicas poderiam haver-se depositado na Terra e sobre as transformações que poderiam ter tido lugar na superfície terrestre, talvez poderíamos ser capazes de desenvolver modelos prospectivos de evolução da informação genética.
História
Descoberta

A história do ADN começa no final da década de 1860, com a chegada do bioquímico e médico suíço Friedrich Miescher (1844-1895) à Universidade de Tübingen, uma pacata cidade no sul da Alemanha. O jovem pesquisador estava disposto à dedicar-se ao estudo da química da célula e escolheu essa universidade porque nela o químico Felix Hoppe-Seyler (1825-1895) havia inaugurado um importante laboratório de química fisiológica. Na época floresciam ideias a respeito das origens e funções das células, após a queda da teoria da geração espontânea. A teoria celular estabelecia-se como um dos pilares da Biologia. Por tudo isso, as células atraíam a atenção de estudantes entusiasmados, como Miescher.
Felix Hoppe-Seyler foi quem primeiro descreveu as interações entre a hemoglobina, a proteína responsável pela cor do sangue, e o gás oxigênio. Seu trabalho levou-o a interessar-se pela composição bioquímica dos linfócitos. Mas Miescher enfrentou dificuldades para obter amostras com linfócitos em quantidade e grau de pureza adequados. Por sugestão de Hoppe-Seyler, Miescher começou a estudar a química das células do pus; o material para a pesquisa era abundante, pois dezenas de bandagens com material purulento eram diariamente descartadas por um hospital próximo à universidade. Miescher desenvolveu técnicas adequadas para o isolamento das células presentes em pus das bandagens e para a sua análise química. O objetivo inicial era investigar as proteínas celulares, um grupo de substâncias descoberto cerca de trinta anos antes.
Em um dos seus muitos experimentos com células do pus, Miescher obteve um precipitado que diferia quimicamente de todas as substâncias protéicas conhecidas. Ele descobriu que a nova substância concentrava-se no núcleo celular, na época considerado uma estrutura de pouca importância para o funcionamento celular. Aprimorando os métodos de extração e purificação da nova substância, Miescher pôde realizar uma análise química mais precisa, que mostrou que as quantidades relativas de hidrogênio, carbono, oxigênio e nitrogênio presentes diferiam das encontradas em proteínas, além de uma quantidade incomum de fósforo. À substância descoberta Miescher denominou nucleína, pelo fato de ela estar concentrada no núcleo das células.
O trabalho sobre nucleína só foi publicado em 1871, após certa resistência do editor da revista científica, o próprio Hoppe-Seyler, que, no início, não acreditou nos resultados apresentados por Miescher. Mesmo depois da publicação do trabalho, muitos pesquisadores continuaram duvidando da existência da nucleína; na opinião deles, o achado de Miescher devia ser uma mistura de fosfato inorgânico e proteínas.
Elucidação da composição química
As desconfianças quanto à real existência da nova substância descrita por Miescher só foram superadas por volta de 1889, quando Richard Altmann (1852-1900) obteve preparações altamente purificadas de nucleína, sem nenhuma contaminação por proteínas. Pelo fato de a substância ter caráter ácido, o que já havia sido detectado por Miescher, Altmann sugeriu que ela fosse chamada de ácido nucléico em vez de nucleína.
Outro pesquisador pioneiro na descoberta foi Albrecht Kossel (1853-1927). Em 1877, ele juntou-se ao grupo de pesquisa de Hoppe-Seyler, então trabalhando na Universidade de Estrasburgo (França), e começou a estudar a composição química das nucleínas. Kossel detectou dois tipos de bases nitrogenadas já conhecidas, a adenina e a guanina. Em 1893, identificou uma nova base nitrogenada, que era liberada pela degradação de nucleína da células do timo; por isso denominou-a timina. Logo em seguida, descobriu que a nucleína continha um quarto tipo de base nitrogenada, a qual denominou citosina. Em 1894, o grupo liderado por Kossel descobriu que os ácidos nucleicos continham também pentose, um açúcar com cinco átomos de carbono. Em reconhecimento às suas contribuições na área, foi agraciado em 1910 com o Nobel de Fisiologia ou Medicina.
Em 1909, Phoebus Levene e Walter Abraham Jacobs (1883-1967) conseguiram determinar a organização das moléculas de fosfato, de pentose e base nitrogenada no ácido nucleico. Esses três componentes estão unidos entre si formando uma unidade fundamental, o nucleotídeo. Em 1929, Levene e colaboradores identificaram pentoses componente do ácido nucleico das células do timo, que denominaram 2-deoxi-D-ribose, pelo fato de ela possuir, no carbono 2 de sua cadeia, um átomo de oxigênio a menos que a ribose, uma pentose já conhecida, encontrada pelos pesquisadores em dois tipos de ácidos nucléicos: o ácido ribonucleico, ou ribose, e o ácido desoxirribonucléico, ou ADN, cujo açúcar é a desoxirribose.
Descoberta da transformação

Frederick Griffith fez uma importante observação no curso dos experimentos com a bactéria Streptococcus pneumoniae em 1928. Esta bactéria, que causa pneumonia em humanos, normalmente é letal em camundongos. Entretanto algumas linhagens desta espécie de bactérias eram menos virulentas (menos capazes de causar doenças ou morte). Nos experimentos de Griffith, ele usou duas linhagens distinguíveis pelas suas colônias quando cultivadas em laboratório. Uma linhagem era um tipo normalmente virulento e mortal para a maioria dos animais de laboratório. As células desta linhagem estão envoltas em uma cápsula de polissacarídeo, dando às colônias em aspecto liso, sendo esta linhagem identificada com S (smooth, em inglês). A outra linhagem de Griffith era um tipo mutante não virulento que crescia em camundongos. Nesta linhagem, a capa de polissacarídeo está ausente, dando às colônias um aspecto rugoso. Esta linhagem é chamada R (rough, em inglês).
Griffith inativou algumas células virulentas a alta temperatura. Injetou então as células mortas por aquecimento nos camundongos. Os camundongos sobreviveram, mostrando que os restos das células não causam morte. Entretanto os camundongos injetados com uma mistura de células virulentas mortas por aquecimento e células não virulentas vivas morreram. Além disso, as células vivas podiam ser recuperadas de camundongos mortos. Estas células deram colônias lisas e foram virulentas em uma injeção subsequente. De algum modo, os restos das células S aquecidas haviam convertido células R vivas em células S vivas.

A etapa seguinte era determinar que componente químico das células doadoras mortas havia causado esta conversão. Esta substância tinha mudado o genótipo da linhagem receptora e portanto podia ser uma candidata a material genético. Este problema foi resolvido pelos experimentos feitos em 1944 por Oswald Avery e dois colegas, C M. Macleod e M. McCarty. Seu enfoque ao problema foi destruir quimicamente todas as principais categorias de substâncias no extrato de células mortas, uma de cada vez, e descobrir se o extrato havia perdido a habilidade de conversão. As células virulentas possuíam uma capa lisa de polissacarídeo, enquanto as células não virulentas, não. Assim os polissacarídeos eram um candidato óbvio a ser o agente responsável. Entretanto, quando os polissacarídeos foram destruídos, a mistura ainda era capaz de conversão. As proteínas, gorduras e ácido ribonucleico (ARN) foram todos excluídos. A mistura só perdia a sua capacidade de conversão quando a mistura doadora era tratada com enzima desoxirribonuclease (DNase), que quebra o ADN. Estes resultados indicavam fortemente que o ADN era o material genético. Hoje sabemos que os fragmentos do ADN transformante que conferem virulência entram no cromossomo bacteriano e substituem suas contrapartes que conferem não virulência.
Experimento de Hershey-Chase

Os experimentos feitos por Avery e seus colegas foram definitivos, mas muitos cientistas mostraram-se muito relutantes em aceitar o ADN (e não as proteínas) como material genético. Evidências adicionais foram publicadas em 1952 por Alfred Day Hershey e Martha Chase, cujo experimento com o fago T2, um vírus que transfecta na bactéria a informação específica para a reprodução viral. Se eles pudessem descobrir que material o fago transmitia à bactéria hospedeira, determinariam o material genético do fago.
O fago tem uma constituição molecular relativamente simples. A maior parte de sua estrutura é de proteína, com o ADN contido dentro da capa de proteína de sua "cabeça". Hershey e Chase decidiram marcar o ADN e a proteína usando radioisótopos, de modo que pudessem rastrear os dois materiais durante a infecção. O fósforo não é encontrado nas proteínas mas é uma parte integrante do ADN. Contrariamente, o enxofre está presente nas proteínas mas nunca no ADN. Hershey e Chase incorporaram o radioisótopo de fósforo (32P) no ADN do fago e o enxofre (35S) nas proteínas de uma cultura separada de fagos. Eles então infectaram duas culturas de E. coli com muitas partículas de vírus por células: uma cultura de E. coli recebeu fagos marcados com 32P e a outra recebeu fagos marcados com 35S. Decorrido tempo suficiente para que ocorresse a infecção, os cientistas removeram as embalagens de fago (chamadas ghosts) das células bacterianas por agitação em um liquidificador. Eles separaram as células bacterianas dos envoltórios dos fagos em uma centrífuga e então mediram a radioatividade nas duas frações. Quando o fago marcado com 32P foi usado para infectar E. coli, a mais alta radioatividade foi encontrada dentro das bactérias, indicando que o ADN do fago havia entrado nas células. Quando era usado o fago marcado com 35S, maior parte do material radioativo estava nos invólucros dos fagos, indicando que a proteína do fago nunca entrava nas bactérias. A conclusão era inevitável: o ADN era o material hereditário. As proteínas do fago eram apenas embalagens estruturais abandonadas após o ADN viral entrar na bactéria.
Aplicações
Engenharia genética
A investigação sobre o ADN tem um impacto significativo, especialmente no âmbito da medicina, mas também na agricultura e pecuária, com objectivos de domesticação, selecção e de cruzamentos dirigidos. A moderna biologia e bioquímica fazem uso intensivo da tecnologia do ADN recombinante, introduzindo genes de interesse em organismos, com o objectivo de expressar uma proteína recombinante concreta, que pode ser:
- isolada para seu uso posterior: por exemplo, podem-se transformar microorganismos para produzir grandes quantidades de substâncias úteis, como a insulina, que posteriormente se isolam e se utilizam em terapias;
- necessária para substituir a expressão de um gene endógeno danificado que seja causador de uma patologia, o que permitiria o restabelecimento da actividade da proteína perdida e eventualmente a recuperação do estado fisiológico normal, não patológico. Este é o objectivo da terapia genética, um dos campos em que se está a trabalhar activamente em medicina, analisando vantagens e inconvenientes de diferentes sistemas de administração do gene (virais e não virais) e os mecanismos de selecção do ponto de integração dos elementos genéticos (distintos para os vírus e transposões) no genoma alvo. Neste caso, antes de apresentar-se a possibilidade de realizar uma terapia génica numa determinada patologia, é fundamental compreender o impacto do gene de interesse no desenvolvimento de dita patologia, para o qual é necessário o desenvolvimento de um modelo animal, eliminando ou modificando dito gene num animal de laboratório, mediante a técnica nocaute. Só no caso de os resultados no modelo animal serem satisfatórios poderá ser analisada a possibilidade de restabelecer o gene danificado mediante terapia génica;
- utilizada para enriquecer um alimento: por exemplo, a composição do leite (que é uma importante fonte de proteínas para o consumo humano e animal) pode modificar-se mediante transgénese, adicionando genes exógenos e inactivando genes endógenos para melhorar o seu valor nutricional, reduzir infecções nas glândulas mamárias, proporcionar aos consumidores proteínas antipatogénicas e preparar proteínas recombinantes para o uso farmacêutico;
- útil para melhorar a resistência do organismo transformado: por exemplo, em plantas podem-se introduzir genes que conferem resistência a agentes patogénicos (vírus, insectos, fungos), assim como a agentes estressantes abióticos (salinidade, seca, metais pesados).
Medicina Forense
A Medicina Forense pode utilizar o ADN presente no sangue, no sémen, na pele, na saliva ou em pelos existentes na cena de um crime para identificar o responsável. Esta técnica denomina-se impressão genética ou perfil de ADN. Ao realizar a impressão genética, compara-se o comprimento de secções altamente variáveis do ADN repetitivo, como os microssatélites, entre pessoas diferentes. Este método é muito fiável para identificar um criminoso. No entanto, a identificação pode complicar-se se a cena do crime estiver contaminada com ADN de pessoas diferentes. A técnica da impressão genética foi desenvolvida em 1984 pelo geneticista britânico Sir Alec Jeffreys, e utilizada pela primeira vez para condenar Colin Pitchfork por causa dos assassinatos de Narborough (Reino Unido) em 1983 e 1986. Pode-se requerer às pessoas acusadas de certos tipos de crimes que cedam uma amostra de ADN para ser introduzida numa base de dados. Isto tem facilitado o trabalho dos investigadores na resolução de casos antigos, onde só se obteve uma amostra de ADN da cena do crime, em alguns casos permitindo exonerar um convicto. A impressão genética também pode ser utilizado para identificar vítimas de acidentes em massa, ou para realizar provas de consanguinidade.
Bioinformática
A Bioinformática implica a manipulação, busca e extracção de informação dos dados da sequência do ADN. O desenvolvimento das técnicas para armazenar e procurar sequências de ADN gerou avanços no desenvolvimento de software para computadores, com muitas aplicações, especialmente algoritmos de busca de frases, aprendizagem automática e teorias de bases de dados. A busca de frases ou algoritmos de coincidências, que procuram a ocorrência de uma sequência de letras dentro de uma sequência de letras maior, desenvolveu-se para buscar sequências específicas de nucleótidos. Em outras aplicações como editores de textos, inclusive algoritmos simples podem funcionar, mas as sequências de ADN podem gerar que estes algoritmos apresentem um comportamento de quase o pior caso, devido ao baixo número de carácteres. O problema relacionado do alinhamento de sequências procura identificar sequências homólogas e localizar mutações específicas que as diferenciam. Estas técnicas, fundamentalmente o alinhamento múltiplo de sequências, utilizam-se ao estudar as relações filogenéticas e a função das proteínas. As colecções de dados que representam sequências do ADN do tamanho de um genoma, tais como as produzidas pelo Projecto Genoma Humano, são difíceis de utilizar sem notações que marcam a localização dos genes e dos elementos reguladores em cada cromossoma. As regiões de ADN que têm padrões associados com genes codificantes de proteínas ou ARN podem identificar-se por algoritmos de localização de genes, o que permite aos investigadores predizer a presença de produtos génicos específicos num organismo mesmo antes que se tenha isolado experimentalmente.
Nanotecnologia de ADN
A nanotecnologia de ADN utiliza as propriedades únicas de reconhecimento molecular de ADN e outros ácidos nucleicos para criar complexos ramificados auto-ensamblados com propriedades úteis. Neste caso, o ADN utiliza-se como um material estrutural, mais que como um portador de informação biológica. Isto conduziu à criação de lâminas periódicas de duas dimensões (ambas baseadas em azulejos, assim como usando o método de "ADN origami"), para além de estruturas em três dimensões em forma de poliedros.
História e antropologia
O ADN armazena mutações conservadas com o tempo e portanto contém informação histórica. Comparando sequências de ADN, os geneticistas podem inferir a história evolutiva dos organismos, a sua filogenia. O campo da filogenia é uma ferramenta potente na biologia evolutiva. Se se compararem as sequências de ADN dentro de uma espécie, os geneticistas de populações podem conhecer a história de populações particulares. Isto pode-se utilizar numa ampla variedade de estudos, desde ecologia até antropologia; por exemplo, evidência baseada na análise de ADN está a ser utilizada para identificar as Dez Tribos Perdidas de Israel.
Ver também
Bibliografia
- Introdução à genética, Riffiths, Wessler, Lewontin, Gesbart, suzuki, Miller, 8º Edição, Guanabara Koogan, 2006.
- Biologia; José Mariano Amabis, Gilberto Rodriges Martho; Moderna; 2004
Ligações externas
- «The Secret Life of DNA - DNA Music compositions» (em inglês)
- «The Register of Francis Crick Personal Papers 1938 - 2007» (em inglês). na Mandeville Special Collections Library, Geisel Library, University of California, San Diego
- «DNA Interactive» (em inglês). Sítio do Dolan DNA Learning Center que inclui dezenas de animações assim como entrevistas com James Watson e outros (requer Adobe Flash)
- «DNA from the Beginning» (em inglês). Sítio da DNA Learning Center sobre DNA, genes e hereditariedade desde Mendel até ao Projecto Genoma Humano
- «Double Helix 1953–2003» (em inglês). National Centre for Biotechnology Education
- «Double helix: 50 years of DNA» (em inglês). , Nature
- «Contribuição de Rosalind Franklin para o estudo do ADN» (em inglês)
- «U.S. National DNA Day» (em inglês). — Veja vídeos e participe em chat em tempo real com cientistas de topo
- «Genetic Education Modules for Teachers» (em inglês). — DNA from the Beginning Study Guide
- «Oiça Francis Crick e James Watson a falar para a BBC en 1962, 1972 e 1974» (em inglês)
- «DNA sob microscópio electrónico» (em inglês)
- «Enrolamento de DNA para formar cromossomas» (em inglês)
- «DISPLAR: Predição de sítios de ligação ao ADN em proteínas» (em inglês)
- «Dolan DNA Learning Center» (em inglês)
- (em inglês) Olby, R. (2003) "Quiet debut for the double helix" Nature 421 (January 23): 402–405.
- «guia básico animado de clonagem de ADN» (em inglês)
- «DNA the Double Helix Game» (em inglês). - Do sítio oficial do Prémio Nobel