
A bioestatística é a aplicação de estatística ao campo biológico e médico, sendo essencial ao planejamento, coleta, avaliação e interpretação de todos os dados obtidos em pesquisa em tais campos. É fundamental à epidemiologia, à ecologia, à psicologia social e à medicina baseada em evidência. A estatística forma uma ferramenta chave nos negócios e na industrialização como um todo. É utilizada a fim de entender sistemas variáveis, controle de processos (chamado de "controle estatístico de processo" ou CEP), custos financeiros (contábil) e de qualidade e para sumarização de dados e também tomada de decisão baseada em dados. Nessas funções ela é uma ferramenta chave e a única ferramenta segura. A estatística é uma ferramenta segura, uma ciência exata. Incorparada ao campo biológico e médico avalia com seguridade dados médicos e biológicos, tendo assim, uma maior segurança nas análises clínicas, com uso de ferramentas avançadas e softwares estatísticos, realizando análises estatísticas sobre o fato ou problema estudado.
História
Bioestatística e genética
A modelação bioestatística constitui uma parte importante de numerosas teorias biológicas modernas. Os estudos genéticos, desde o seu início, utilizaram conceitos estatísticos para compreender os resultados experimentais observados. Alguns cientistas da genética contribuíram mesmo com avanços estatísticos com o desenvolvimento de métodos e ferramentas. Gregor Mendel iniciou os estudos genéticos investigando os padrões de segregação genética em famílias de ervilhas e utilizou estatísticas para explicar os dados recolhidos. No início do século XIX, após a redescoberta do trabalho de Mendel sobre a herança Mendeliana, houve lacunas na compreensão entre a genética e o darwinismo evolutivo. Francis Galton tentou expandir as descobertas de Mendel com dados humanos e propôs um modelo diferente com fracções da hereditariedade provenientes de cada antepassado, compondo uma série infinita. Ele chamou a isto a teoria da "Lei da Hereditariedade Ancestral". As suas ideias foram fortemente contestadas por William Bateson, que seguiu as conclusões de Mendel, segundo as quais a herança genética provinha exclusivamente dos pais, metade de cada um deles. Isto levou a um debate vigoroso entre os biometristas, que apoiaram as ideias de Galton, como Raphael Weldon, Arthur Dukinfield Darbishire e Karl Pearson, e Mendelianos, que apoiaram as ideias de Bateson (e de Mendel), como Charles Davenport e Wilhelm Johannsen. Mais tarde, os biometristas não puderam reproduzir as conclusões de Galton em diferentes experiências, e as ideias de Mendel prevaleceram. Na década de 1930, modelos construídos com base no raciocínio estatístico tinham ajudado a resolver estas diferenças e a produzir a síntese evolucionária moderna neo-darwinista.
A resolução destas diferenças permitiu também definir o conceito de genética da população e reuniu a genética e a evolução. As três figuras principais no estabelecimento da genética populacional e esta síntese basearam-se todas em estatísticas e desenvolveram a sua utilização em biologia.
- Ronald Fisher desenvolveu vários métodos estatísticos básicos em apoio ao seu trabalho de estudo das experiências de culturas na Rothamsted Research, incluindo nos seus livros Statistical Methods for Research Workers (1925) end The Genetical Theory of Natural Selection (1930). Deu muitas contribuições para a genética e estatística. Algumas delas incluem a ANOVA, conceitos de valor-p, o teste exacto de Fisher e a equação de Fisher para a dinâmica populacional. Ele é creditado pela frase "A selecção natural é um mecanismo para gerar um grau excessivamente elevado de improbabilidade".
- Sewall G. Wright desenvolveu estatísticas F e métodos de cálculo das mesmas e definiu o coeficiente de consanguinidade.
- O livro de J. B. S. Haldane The Causes of Evolution, restabeleceu a seleção natural como o principal mecanismo da evolução, explicando-a em termos das consequências matemáticas da genética Mendeliana. Também desenvolveu a teoria da sopa primordial.
Estes e outros bioestatísticos, biólogos matemáticos e geneticistas estatisticamente inclinados ajudaram a reunir a biologia evolutiva e a genética num todo consistente e coerente que poderia começar a ser modelado quantitativamente.
Paralelamente a este desenvolvimento global, o trabalho pioneiro de D'Arcy Thompson em Sobre Crescimento e Forma também ajudou a acrescentar disciplina quantitativa ao estudo biológico.
Apesar da importância fundamental e da necessidade frequente de raciocínio estatístico, pode ter existido uma tendência entre os biólogos para desconfiar ou depreciar resultados que não são qualitativamente aparentes. Uma anedota descreve Thomas Hunt Morgan a proibir a calculadora Friden do seu departamento na Caltech, dizendo "Bem, eu sou como um tipo que prospecta ouro ao longo das margens do rio Sacramento em 1849. Com um pouco de inteligência, posso descer e apanhar grandes pepitas de ouro. E enquanto puder fazer isso, não vou deixar que nenhuma pessoa do meu departamento desperdice recursos escassos na mineração de placar".
Planeamento da investigação
Qualquer investigação em ciências da vida é proposta para responder a uma questão científica que possamos ter. Para responder a esta pergunta com uma elevada certeza, precisamos de resultados precisos. A definição correta da hipótese principal e do plano de investigação reduzirá os erros ao mesmo tempo que se toma uma decisão na compreensão de um fenômeno. O plano de investigação poderá incluir a questão da investigação, a hipótese a ser testada, a concepção experimental, os métodos de recolha de dados, as perspectivas de análise de dados e os custos evoluídos. É essencial realizar o estudo com base nos três princípios básicos da estatística experimental: randomização, replicação, e controle local.
Pergunta de investigação
A questão da investigação irá definir o objetivo de um estudo. A investigação será encabeçada pela pergunta, pelo que precisa de ser concisa, ao mesmo tempo que se concentra em tópicos interessantes e inovadores que podem melhorar a ciência e o conhecimento e esse campo. Para definir a forma de colocar a questão científica, poderá ser necessária uma exaustiva revisão bibliográfica. Assim, a investigação pode ser útil para acrescentar valor à comunidade científica.
Definição de hipótese
Uma vez definido o objetivo do estudo, podem ser propostas as possíveis respostas à questão da investigação, transformando esta questão numa hipótese. A proposta principal chama-se hipótese nula (H0) e baseia-se geralmente num conhecimento permanente sobre o tema ou numa ocorrência óbvia do fenómeno, sustentado por uma profunda revisão da literatura. Podemos dizer que é a resposta padrão esperada para os dados sob a situação em teste. Em geral, HO não assume qualquer associação entre tratamentos. Por outro lado, a hipótese alternativa é a negação de HO. Pressupõe algum grau de associação entre o tratamento e o resultado. Embora, a hipótese seja sustentada por pesquisas de perguntas e pelas suas respostas esperadas e inesperadas.
Como exemplo, considerar grupos de animais semelhantes (ratos, por exemplo) sob dois sistemas alimentares diferentes. A questão de investigação seria: qual é a melhor dieta? Neste caso, H0 seria que não há diferença entre as duas dietas no metabolismo dos ratos (H0: μ1 = μ2) e a hipótese alternativa seria que as dietas têm efeitos diferentes sobre o metabolismo dos animais (H1: μ1 ≠ μ2).
A hipótese é definida pelo investigador, de acordo com os seus interesses em responder à pergunta principal. Além disso, a hipótese alternativa pode ser mais do que uma hipótese. Pode assumir não só diferenças entre os parâmetros observados, mas também o seu grau de diferença (ou seja, maior ou menor).
Amostragem
Normalmente, um estudo visa compreender um efeito de um fenômeno sobre uma população. Em biologia, uma população é definida como todos os indivíduos de uma determinada espécie, numa área específica e num determinado momento. Na bioestatística, este conceito é alargado a uma variedade de coleções possíveis de estudo. Embora, em bioestatística, uma população não seja apenas os indivíduos, mas o total de um componente específico dos seus organismos, como o genoma inteiro, ou todas as células espermáticas, para os animais, ou a área total da folha, para uma planta, por exemplo.
Não é possível tomar as medidas a partir de todos os elementos de uma população. Devido a isso, o processo de amostragem é muito importante para a inferência estatística. A amostragem é definida de forma a obter aleatoriamente uma parte representativa de toda a população, para fazer inferências posteriores sobre a população. Assim, a amostra pode apanhar a maior variabilidade entre uma população. O tamanho da amostra é determinado por várias coisas, desde o âmbito da investigação até aos recursos disponíveis. Na investigação clínica, o tipo de ensaio, como inferioridade, equivalência, e superioridade, é uma chave na determinação do tamanho da amostra.
Desenho experimental
Os desenhos experimentais sustentam esses princípios básicos das estatísticas experimentais. Existem três desenhos experimentais básicos para atribuir tratamentos aleatórios em todas as parcelas da experiência. São desenhos completamente randomizados, desenhos de blocos aleatórios, e desenhos fatoriais. Os tratamentos podem ser dispostos de muitas maneiras dentro da experiência. Na agricultura, o desenho experimental correto é a raiz de um bom estudo e a disposição dos tratamentos dentro do estudo é essencial porque o ambiente afeta largamente as parcelas (plantas, gado, microrganismos). Estes arranjos principais podem ser encontrados na literatura sob os nomes de "treliças", "blocos incompletos", "parcela dividida", "blocos aumentados", e muitos outros. Todos os desenhos podem incluir parcelas de controle, determinadas pelo investigador, para fornecer uma estimativa de erro durante a inferência.
Em estudos clínicos, as amostras são geralmente mais pequenas do que noutros estudos biológicos, e na maioria dos casos, o efeito ambiental pode ser controlado ou medido. É comum utilizar ensaios clínicos controlados randomizados, onde os resultados são normalmente comparados com desenhos de estudos observacionais, tais como caso-controle ou coorte.
Coleta de dados
Os métodos de coleta de dados devem ser considerados no planeamento da investigação, porque influenciam fortemente o tamanho da amostra e a concepção experimental.
A recolha de dados varia de acordo com o tipo de dados. Para os dados qualitativos, a recolha pode ser feita com questionários estruturados ou por observação, considerando a presença ou intensidade da doença, utilizando o critério de pontuação para categorizar os níveis de ocorrência. Para os dados quantitativos, a recolha é feita através da medição de informação numérica utilizando instrumentos.
Em estudos de agricultura e biologia, os dados de rendimento e os seus componentes podem ser obtidos por medidas métricas. No entanto, as lesões por pragas e doenças em placas são obtidas por observação, considerando escalas de pontuação para níveis de danos. Especialmente em estudos genéticos, devem ser considerados métodos modernos de recolha de dados no campo e em laboratório, como plataformas de alto rendimento para fenotipagem e genotipagem. Estas ferramentas permitem experiências maiores, enquanto tornam possível avaliar muitas parcelas em menos tempo do que um método de recolha de dados baseado apenas em humanos. Finalmente, todos os dados recolhidos de interesse devem ser armazenados num quadro de dados organizado para posterior análise.
Análise e interpretação de dados
Ferramentas descritivas
Os dados podem ser representados através de tabelas ou representação gráfica, tais como gráficos de linhas, gráficos de barras, histogramas, gráfico de dispersão. Além disso, medidas de tendência central e variabilidade podem ser muito úteis para descrever uma visão geral dos dados. Siga alguns exemplos:
Tabelas de frequência
Um tipo de tabelas é a tabela de frequência, que consiste em dados dispostos em linhas e colunas, em que a frequência é o número de ocorrências ou repetições de dados. A frequência pode ser:
Absoluta: representa o número de vezes que determinado valor aparece;

Relativa: obtida pela divisão da frequência absoluta pelo número total;

No exemplo seguinte, temos o número de genes em dez operãos do mesmo organismo.
Genes = 2,3,3,4,5,3,3,3,3,4
| Número de genes | Frequência absoluta | Frequência relativa |
|---|---|---|
| 1 | 0 | 0 |
| 2 | 1 | 0.1 |
| 3 | 6 | 0.6 |
| 4 | 2 | 0.2 |
| 5 | 1 | 0.1 |
Gráfico de linha
Os gráficos de linha representam a variação de um valor sobre outra métrica, tal como o tempo. Em geral, os valores são representados no eixo vertical, enquanto que a variação do tempo é representada no eixo horizontal.
Gráfico de barras
Um gráfico de barra é um gráfico que mostra dados categóricos como barras que apresentam alturas (barra vertical) ou larguras (barra horizontal) proporcionais para representar valores. Os gráficos de barras fornecem uma imagem que também poderia ser representada num formato tabular.
Histograma
O histograma (ou distribuição de frequência) é uma representação gráfica de um conjunto de dados tabelados e divididos em classes uniformes ou não uniformes. Foi introduzido pela primeira vez por Karl Pearson.
Gráfico de dispersão
Um gráfico de dispersão é um diagrama matemático que utiliza coordenadas cartesianas para exibir valores de um conjunto de dados. Um gráfico de dispersão mostra os dados como um conjunto de pontos, cada um apresentando o valor de uma variável determinando a posição no eixo horizontal e outra variável no eixo vertical.
Média
A média aritmética é a soma de uma coleção de valores () dividido pelo número total de valores ().



Mediana
Mediana é o valor que separa a metade maior e a metade menor de uma amostra, uma população ou uma distribuição de probabilidade.
Moda
Moda de um conjunto de dados trata do valor que ocorre com maior frequência ou o valor mais comum em um conjunto de dados.
Diagrama de caixa (Box plot)

Diagrama de caixa é um método para representar graficamente grupos de dados numéricos. Os valores máximo e mínimo são representados pelas linhas e a caixa representa a mediana e o intervalo interquartil representa 25–75% dos dados. Dados extrapolantes (Outliers) podem ser plotados como círculos.
Intervalo de confiança
Um intervalo de confiança é uma faixa de valores que pode conter o valor real do parâmetro em um determinado nível de confiança. O primeiro passo é estimar a melhor estimativa imparcial do parâmetro populacional. Os limites de confiança são obtidos pela soma e subtração desta estimativa com o erro padrão.
Coeficiente de correlação de Pearson
Embora a correlação entre dois tipos diferentes de dados possa ser inferida por meio de gráficos, tais como o gráfico de dispersão, é necessário validar isso por meio de informações numéricas. Por esta razão, o coeficiente de correlação é necessário. Ele fornece um valor numérico que reflete a força de uma associação.
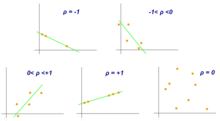
O Coeficiente de correlação de Pearson é uma medida de associação entre duas variáveis, X e Y . Este coeficiente, normalmente representado por ρ (rho) para a população e r para a amostra, assume valores entre -1 e 1, onde ρ = 1 representa uma correlação positiva perfeita, ρ = −1 representa uma correlação negativa perfeita e ρ = 0 significa não existir nenhuma correlação linear.
Inferência estatística
- Nível de significância e regra de decisão: Uma regra de decisão depende do nível de significância, ou seja, da taxa de erro aceitável (α) para rejeitar erroneamente a hipótese nula (H0). É mais fácil pensar que definimos um valor crítico que determina quando uma estatística de teste rejeita a hipótese nula (H0). Assim, α também deve ser pré-definido antes do experimento.
- Inferência estatística: É feita quando a hipótese nula é rejeitada ou não, com base na evidência do resultado de um teste estatístico, no qual há a comparação de valor de p e α (nível de significância). Aponta-se que a não rejeição de H0 significa apenas que não há evidências suficientes para sustentar sua rejeição, mas não que essa hipótese seja verdadeira.
Considerações estatísticas
Valor de p
O valor de p é a probabilidade dos resultados (amostras observadas) de serem obtidos a partir da população de referência, assumindo que a hipótese nula (H0) seja verdadeira. Também é chamada de probabilidade calculada, nível descritivo ou probabilidade de significância. É comum confundir o valor de p com o nível de significância (α), mas o α é um limiar predefinido para decidir se resultado é estatisticamente significativo. Se p for menor que α, a hipótese nula (H0) é rejeitada.
Erros estatísticos e Poder do teste estatístico
Ao testar uma hipótese, existem dois tipos de erros estatísticos possíveis: Erro tipo I e Erro tipo II (veja a tabela abaixo). O erro tipo I ou falso positivo é a rejeição incorreta de uma hipótese nula verdadeira e o erro tipo II ou falso negativo é a falha em rejeitar uma hipótese hipótese nula falsa. O nível de significância denotado por α é a taxa de erro tipo I e deve ser escolhido antes da realização do teste. A taxa de erro tipo II é denotada por β e o Poder do teste estatístico é 1 − β.
| A hipótese H0 é verdadeira | A hipótese H0 é falsa | |
|---|---|---|
| Rejeita-se H0 | Erro do tipo I | sem erro |
| Não se rejeita H0 | sem erro | Erro do tipo II |