
Análise de sobrevivência, também denominada análise de sobrevida, é um ramo da estatística que estuda o tempo de duração esperado até a ocorrência de um ou mais eventos, tais como morte em organismos biológicos e falha em sistemas mecânicos. Em engenharia este tema é denominado teoria da confiabilidade ou análise de confiabilidade; em economia é conhecido como análise de duração ou modelagem de duração e, em sociologia, como análise da história do evento. A análise de sobrevivência procura responder perguntas como: qual é a proporção de uma população que sobreviverá depois de um certo tempo? Daqueles que sobrevivem, a que ritmo eles vão morrer ou falhar? Podem várias causas de morte ou falha ser levado em conta? Como circunstâncias ou características específicas aumentam ou diminuem a probabilidade de sobrevivência?
Para responder às perguntas listadas, é necessário definir lifetime, isto é, tempo de vida. No caso da sobrevivência biológica, morte é um desfecho inequívoco, mas para confiabilidade mecânica, falha pode não estar bem definida, pois existem sistemas mecânicos em que a falha é parcial, estar sujeita a graus ou não estar localizada no tempo. Mesmo em problemas biológicos, alguns eventos (por exemplo, ataque cardíaco ou outra falência de órgãos) podem ter a mesma ambiguidade da falhas parciais. A teoria descrita abaixo assume eventos bem definidos em momentos específicos; outros casos podem ser melhor tratados por modelos que explicitamente explicam eventos ambíguos.
De modo mais geral, a análise de sobrevivência envolve a modelagem do tempo para os dados do evento. Nesse contexto, a morte ou o fracasso é considerado um "evento" na literatura de análise de sobrevivência – tradicionalmente apenas um único evento ocorre para cada sujeito, após o qual o organismo ou mecanismo está morto ou quebrado. Modelos de Evento recorrente ou evento repetido relaxam essa suposição. O estudo de eventos recorrentes é relevante em confiabilidade dos sistemas, e em muitas áreas de ciências sociais e pesquisa médica.
Vale destacar que, na modelagem do tempo de sobrevivência, as técnicas estatísticas padrão geralmente não podem ser aplicadas porque a distribuição subjacente raramente é normal e os dados são, muitas vezes, "censurados".
Introdução à análise de sobrevivência
A análise de sobrevivência é usada de várias maneiras:
- Para descrever os tempos de sobrevivência dos membros de um grupo por meio de:
- Para comparar os tempos de sobrevivência de dois ou mais grupos:
- Para descrever o efeito de variáveis categóricas ou quantitativas na sobrevivência:
- Regressão de riscos proporcionais de Cox
- Modelos paramétricos de sobrevivência
- Árvores de sobrevivência
- Florestas aleatórias de sobrevivência
Definições de termos comuns na análise de sobrevivência
Os seguintes termos são comumente usados em análises de sobrevivência:
- EVENTO - Morte, ocorrência de doença, recorrência da doença, recuperação ou outra experiência de interesse
- TEMPO - O tempo desde o início de um período de observação (como cirurgia ou início de tratamento) até (i) ocorrer um evento, ou (ii) finalizar o estudo, ou (iii) ocorrer a perda de contato ou retirada do estudo.
- CENSURA - Se um sujeito não experimenta um evento durante o tempo de observação ele será descrito como censurado. O sujeito é censurado no sentido em que nada é observado ou conhecido sobre ele após o tempo de censura. Um sujeito censurado pode ou não ter um evento após o final tempo de observação.
- FUNÇÃO DE SOBREVIVÊNCIA - É uma função, S, que associa a cada tempo t o número S (t) que é a probabilidade de que um sujeito sobreviva além do tempo t.
Exemplo: dados de sobrevivência à leucemia mielóide aguda (aml)
Descrição da base de dados
Este exemplo usa o conjunto de dados "aml" do pacote de "survival" do software R. O conjunto de dados é de Miller(1997) e a questão, em estudo, é se o curso padrão da quimioterapia deve ser estendido ('mantido') para ciclos adicionais.
O conjunto de dados "aml", classificado pelo tempo de sobrevivência, é exibido na Tabela.1, onde:

- O tempo é indicado pela variável "time" e corresponde ao tempo de sobrevivência ou censura;
- O evento (recorrência da aml) é indicado pela variável "status" na qual 0 = não ocorrência do evento ou ocorrência de censura, e 1 = ocorrência do evento (recorrência da aml);
- os tratamentos são representado pelos valores da variável "x" que indica se a quimioterapia de manutenção foi dada ou não
De acordo com a Tabela.1, o sujeito 11 foi censurada (status = 0) na semana 161 semanas. A censura indica que o sujeito não experimentou um evento (não experimentou recorrência de aml). O sujeito 3, foi censurado na 13a. semana. Esse sujeito esteve no estudo por apenas 13 semanas, e a aml não recorreu durante essas 13 semanas. É possível que esse paciente tenha sido incluído perto do final do estudo, para que pudessem ser observados por apenas 13 semanas. Também é possível que o paciente tenha sido incluído no início do estudo, mas tenha perdido acompanhamentos ou se retirado do estudo. A tabela mostra que outros sujeitos foram censurados em 16, 28 e 45 semanas (observações 17, 6, e 9 com status=0). Os demais sujeitos experimentaram o evento (recorrência da aml) durante o período em estudo. Aqui a questão de interesse é se a recorrência ocorre mais tarde em pacientes mantidos do que em pacientes não mantidos.
Kaplan-Meier plot para os dados aml
A função de sobrevivência S(t) é a probabilidade de um sujeito sobrevive mais do que o tempo t. A curva descrita por S(t) é, teoricamente, uma curva suave, sem pontos angulosos, mas, geralmente ela é estimada por meio da curva de Kaplan-Meier (curva KM) que é uma curva com pontos angulosos que lembra uma escada. Em geral na curva KM:
- O eixo horizontal indica o tempo, que vai do zero (quando a observação começou) até o último ponto de tempo observado.
- O eixo vertical indica a proporção de sujeitos sobreviventes. No momento zero, 100% dos sujeitos estão vivos e não experimentaram o evento.
- A linha sólida (semelhante a uma escada) mostra a progressão das ocorrências do evento. Uma queda vertical indica a ocorrência do evento. Considerando a Tabela.1, mostrada acima, é possível observar que dois sujeitos experimentaram o evento em cinco semanas, dois em oito semanas, um teve um evento em nove semanas, e assim por diante. Estes eventos em cinco semanas, oito semanas e assim por diante são indicados pelas "quedas" verticais na curva KM nos instantes referidos.
- Na extremidade direita da curva KM há uma marca vertical em 161 semanas. A marca indica que um paciente foi censurado nesse tempo. Na tabela de dados aml, cinco indivíduos foram censurados, em 13, 16, 28, 45 e 161 semanas. Há cinco marcas verticais na curva KM, correspondentes a estas observações censuradas.
Tabela de vida para os dados aml
Uma tabela de sobrevida resume os dados de sobrevivência em termos do número de eventos e da proporção de sobreviventes em cada ponto de tempo do evento. A tabela de vida para os dados aml, criado usando o software R é mostrada na Tabela.2.
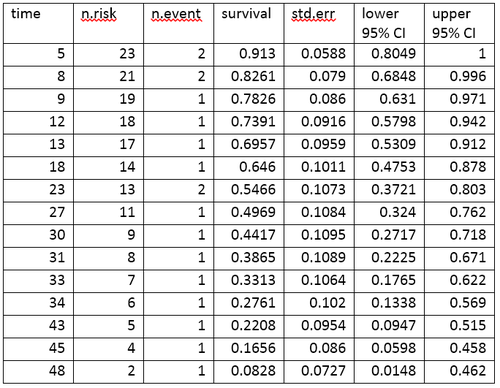
A tabela de vida resume os eventos e a proporção de sujeitos que sobrevivem em cada ponto de tempo do evento. As colunas na tabela de vida têm a seguinte interpretação:
- "time" dá os pontos de tempo em que os eventos ocorrem.
- "n.risk" é o número de sujeitos em risco de experimentar o evento imediatamente antes do instante t. Aqui "estar em risco" significa que o sujeito não experimentou o evento antes do tempo t, e não foi censurado antes ou no instante t.
- "n.event" é o número de sujeitos que experimentaram o evento no instante t.
- "survival" é a proporção de sobreviventes estimada pelo produto-limite KM
- "std.err" é o erro padrão da "survival" estimada. O erro padrão da estimativa do limite de produto-limite KM é calculado usando a fórmula de Greenwood, e depende do "n.risk", do "n.event" e da "survive".
- "lower 95%CI and upper 95%IC" são os limites de confiança inferiores e superiores de 95% para a proporção sobrevivente.
Teste log-rank: Teste para diferenças de sobrevida nos dados aml
O teste log-rank compara os tempos de sobrevivência de dois ou mais grupos. O exemplo que estamos estudando usa um teste log-rank para avaliar a diferença na sobrevida nos grupos de tratamento mantidos versus não mantidos nos dados de aml. A Figura.1 mostra curvas KM para os dados aml de acordo com o grupo de tratamento, que é indicado pela variável "x" nos dados.
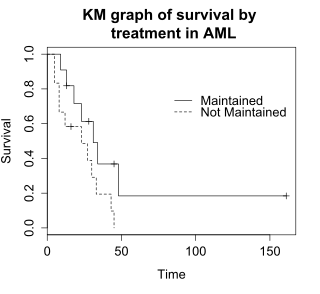
A hipótese nula para um teste log-rank afirma que os grupos têm a mesma curva de sobrevivência. O número esperado de indivíduos que sobrevivem em cada instante é ajustado para o número de indivíduos em risco nos grupos em cada instante do evento. O teste log-rank determina se o número observado de eventos em cada grupo é significativamente diferente do número esperado. O teste formal é baseado em uma estatística qui-quadrado. Quando a maior o valor da estatística log-rank, maior a evidência a favor de uma diferença nos tempos de sobrevivência entre os grupos. A estatística log-rank tem aproximadamente uma qui-quadrado com um grau de liberdade.
Para os dados de exemplo, o teste de log-rank produziu um valor de 3,4982 equivalente a um p-valor de p=0,0614 que é maior que 0,05, indicando que os grupos de tratamento não diferem significativamente quanto a suas curvas de sobrevivência, assumindo um nível alfa de 0,05. O tamanho da amostra de 23 indivíduos é modesto, portanto, há pouca potência para detectar diferenças entre os grupos de tratamento. Além disso, o uso exclusivo do p-valor no processo decisório tem limitações que passam pela sua precisa interpretação .
Regressão de riscos proporcionais de Cox
As curvas KM e os testes log-rank são mais úteis quando a variável preditora é categórica (por exemplo, droga vs. placebo), ou toma um pequeno número de valores (por exemplo, doses: 0, 20, 50 e 100 mg/day) de modo a serem tratadas como categóricas. O teste log-rank e as curvas KM não funcionam muito bem com preditores quantitativos, tais como expressão gênica, contagem de glóbulos brancos ou idade. Para variáveis preditoras quantitativa, um método alternativo é a regressão de riscos proporcionais de Cox (modelos RP de Cox). Os modelos RP de Cox também funcionam com variáveis preditoras categórica, que são codificadas como variáveis dicotômicas {0,1}. O teste log-rank é um caso especial de uma análise RP de Cox.
Exemplo: análise de regressão de riscos proporcionais de Cox para melanoma
Este exemplo usa o conjunto de dados de melanoma do Capítulo 12 de Dalgaard. Os dados estão disponíveis no pacote "ISwR" do R. A regressão dos riscos proporcionais de Cox usando R dá os resultados mostrados na Tabela.3.

Os resultados da regressão de Cox são interpretados da seguinte forma:
- A variável Sex é codificado como um vetor numérico (1: feminino, 2: masculino). O função "summary" do R para o modelo Cox dá a razão de risco de melanoma (RH) para o segundo grupo em relação ao primeiro grupo, ou seja, masculino versus feminino.
- coef=0,662" é o logaritmo estimado da relação de risco para machos versus fêmeas.
- exp(coef)=1,94=exp(0,662) - O log da razão de risco (coef=0,662) é transformado em razão de riscos usando exp(coef). O resumo do modelo Cox dá a razão de risco para o segundo grupo em relação ao primeiro grupo, ou seja, masculino versus feminino. A razão de risco estimada de 1,94 indica que os homens têm maior risco de morte (menores taxas de sobrevivência) do que as mulheres. De fato diz que o risco de melanoma em homens é 1,94 vezes o risco de melanoma em mulheres.
- se(coef) = 0,265 é o erro padrão do log da razão de risco.
- z = 2,5 = coef/se(coef) = 0,662/0,265. Quando dividimos o "coef" por seu erro padrão resulta a pontuação z.
- p=0,013. É o p-valor associado a z=2.5. Para o sexo ele é p=0.013, indicando que há uma diferença significativa na sobrevivência em relação ao sexo (os agrupamentos sexuais tem curvas de sobrevivência diferentes)
A Tabela.3 também oferece os limites de confiança de 95% superior e inferior para a razão de riscos: inferior = 1,15 e superior = 3,26.
Finalmente, a tabela oferece p-valores para três testes alternativos para a significância geral do modelo:
- O "Likelihood ratio test" = 6,15 com 1 glib, p=0,013
- O "Wald test" = 6,24 com 1 glib, p=0,012
- O "Score (logrank) test" = 6,47 com 1 glib, p=0,011
Estes três testes são assintoticamente equivalentes, isto é, para "n" suficientemente grande, eles vão dar resultados semelhantes. Para "n" pequeno, eles podem diferir um pouco. A última linha, "Score (logrank) test" é o resultado para o teste de log-rank, porque o teste log-rank é um caso especial da regressão PH de Cox. O "Likelihood ratio test" comporta-se melhor para amostra pequenas, por isso ele é geralmente preferido.